How's that data lake?

What’s a data lake?#
A “data lake” is a single data store that ideally holds all of an enterprise’s data. The benefit of a lake architecture is that you can safely and easily access your data from many end-points such as dashboards, user-facing applications, or even your CRM. Ed Dumbill has a good overview in Forbes here.
If you’ve never been able to use all your data together before—and most companies have not—then a data lake is a huge improvement. So the idea is popular.
I don’t love data lakes#
I don’t love data lakes for three reasons:
- They leave thorny questions like “reuse”, and “validity” to individual application implementers, rather than providing an architecturally consistent framework to address those problems—and that means that too often they are dumping grounds for data. Sure, everything ends up there, and if you’re willing to take the time to pick through it, you can find some real gems.
- They are a top-down technology choice. Let’s say you implement your lake in Hadoop. Should everything be in Hadoop, or would it make sense for some data to only reside in Cassandra, or S3 or some other store? You must choose whether to take on the complexity and cost of mirroring everything to Hadoop or just accepting that Hadoop is the only tool you will use.
- The most important reason I don’t like lakes is that they don’t do anything. They just sit there.
I do love data pipelines#
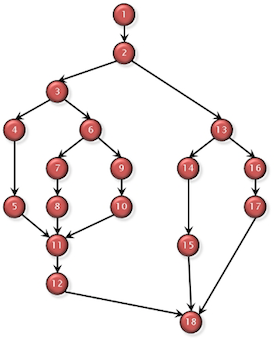 A data pipeline is a directed execution graph with multiple cleanly separated data processing steps, which are like small, clear pools: easy to know what’s in there.
A data pipeline is a directed execution graph with multiple cleanly separated data processing steps, which are like small, clear pools: easy to know what’s in there.
Here’s why they’re great:
- Decouples processing steps (such as cleaning, aggregating, joining) from the ultimate use of the data. That means easy reuse, validation, and parallelization across software engineers when building.
- Technology agnostic so you can use the right tool for each job.
- Data lineage is easier to track and easier to assure freshness
- Any size As a bonus, they can be run quickly on small sets of data, or run on large historical sets of data without changing code.
But most importantly a data pipeline does something. It could be joining and cleaning data, or it could be NLP, or clustering users, or generating personal recommendations — but whatever it is, pipelines aren’t just a repository, they get you closer to solving your business problem in a reusable way.

Data Directory#
Data lakes are universal places to put data. Data pipelines are universal means of coordinating data movement and processing. Data lakes represent a top-down technology choice which provides little or no built-in insight into how the data got there. Data pipelines are technology-agnostic, can read data from anywhere and put it anywhere, and make data provenance clear.
But they both have a weakness: they both require a data directory to be ready for enterprise use. I don’t know of an excellent solution to the data directory problem. Netflix built Franklin but unfortunately they have not yet open sourced it.
 Anyhow, about a year ago at Mortar (acq. Datadog) we recognized the need that our customers have for data pipelines, and decided to figure out the best way to support them. Our requirements were:
Anyhow, about a year ago at Mortar (acq. Datadog) we recognized the need that our customers have for data pipelines, and decided to figure out the best way to support them. Our requirements were:
- Open, no lock-in
- Code-based. Our users must be able to express any task, not just what is baked into a GUI.
- Graphical view so execution may be easily understood
- Universal, works with any technology (e.g. not just with Hadoop)
We tried out Oozie, Azkaban, AWS Data Pipeline, Luigi, and several others. Luigi was the clear winner. It was the only framework that met all our criteria, and besides — it is elegant, and is growing rapidly.
In Luigi, each processing step is described separately in Python. When a specific step is requested, it checks its dependencies, if necessary refreshes them, and then runs. Luigi is the pipeline orchestrator, and delegates actual processing to other technologies which could be Hadoop, or R, or Redshift, or anything else.
Most every major enterprise has built an in-house data pipelining framework, and almost without exception, they are all brittle, awful balls of duct-tape, that are too temperamental and core to be ripped out. Spotify is the exception because they built an amazing data pipelining tool: Luigi. But even they didn’t get it right on the first try. Luigi is their third data pipelining platform. Today it runs all of their production workloads. A few months ago they had a crisis in their staging environment, but were able to create a complete, brand-new set of data for their staging environment with one command, in a few hours. One of Luigi’s creators, Erik Bernhardsson, recently spoke about Luigi at the data science meetup we organize. Video and transcript here.
Put your data to work#
To maximize correctness, speed to market, and innovation, I believe all enterprises need flexible data pipelines to manage their data. Even if a data lake is already part of your architecture, I recommend that you start using pipelines, too.
Update: Mortar is no longer an independent company, so the following won’t work. Want to experience the power of data pipelines and Luigi firsthand, without spending a lot of time experimenting? Request a Mortar account then follow our tutorial for building an end-to-end recommendation engine with Luigi: fork, run. You’ll have a recommendation engine in minutes. That’s the power of pipelines.
More info on Luigi